Opened at 2007-07-08T08:30:14Z
Closed at 2007-07-16T20:45:43Z
#80 closed defect (fixed)
storage format is awfully inefficient for small shares
| Reported by: | warner | Owned by: | warner |
|---|---|---|---|
| Priority: | major | Milestone: | 0.5.0 |
| Component: | code | Version: | 0.4.0 |
| Keywords: | storage | Cc: | |
| Launchpad Bug: |
Description
Eventually we're going to need to revisit our StorageServer? implementation. The current approach stores each share in a separate directory, puts the share itself in 'data' and puts the other metadata in its own files. This results in about 7 files per share.
This approach is nice and simple and understandable and browsable, but not particularly efficient (at least under ext3). For a 20-byte share (resulting from a 476-byte file), the directory appears to consume about 33kB, and the parent directory (which holds 58 such shares for the same file) appears to consume 2MB. This is probably just the basic disk-block quantization that most filesystems suffer from. Lots of small files are expensive.
Testing locally, it looks like concatenating all of the files for a single (884-byte) share reduces the space consumed by that share from 33kB to 8.2kB. If we move that file up a level, so that we don't have a directory-per-share, just one file-per-share, then the space consumed drops to 4.1kB.
So I'm thinking that in the medium term, we either need to move to reiserfs (which might handle small files more efficiently) or change our StorageServer? to try and put all the data in a single file, which means committing to some of the metadata and pre-allocating space for it in the sharefile.
Attachments (2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (12)
comment:1 Changed at 2007-07-08T15:55:20Z by warner
comment:2 Changed at 2007-07-08T16:17:24Z by warner
Oh, and the tahoe-storagespace munin plugin stops working with that many directories. I rewrote it to use the native /usr/bin/du program instead of doing the directory traversal in python, and it still takes 63 seconds to measure the size of all three storageservers on testnet, which is an order of magnitude more than munin will allow before it gives up on the plugin (remember these get run every 5 minutes). It looks like three storageservers-worth of share directories is too large to fit in the kernel's filesystem cache, so measuring all of them causes thrashing. (in contrast, measuring just one node's space takes 14s the first time and just 2s each time thereafter).
So the reason that the storage space graph is currently broken is because the munin plugin can't keep up.
comment:3 Changed at 2007-07-12T18:59:37Z by warner
Zooko and I did some more analysis:
- at the moment, each file is encoded into 100 shares, regardless of how many nodes are present in the mesh at that time
- for small files (less than 2MB) each share has 846 bytes of overhead.
- each share is stored in a separate directory, in 7 separate files (of which the actual share data is one, the uri_extension is a second, and the various hashes and pieces of metadata are others)
- on most filesystems (i.e. ext3), each file and directory consumes at minimum a single disk block
- on filesystems that are larger than a few gigabytes, each disk block is 4096 bytes
- as a result, in the 0.4.0 release, each share consumes a minimum of 8*4096=32768 bytes.
- for tiny files, 1 of these bytes is share data, 846 is validation overhead, and 31921 are filesystem quantization lossage
- so for small files, we incur 1511424 (1.5MB) of disk usage per file (totalled across all 100 shares, on all the blockservers). This usage is constant for filesizes up to about 100kB.
Our plans to improve this:
- #84: produce fewer shares in small networks, by having the introducer suggest 3-of-10 instead of 25-of-100 by default, for a 10x improvement
- #85: store shares in a single file rather than 7 files and a directory, for an 8x improvement
- #81: implement LIT uris, which hold the body of the file inside the URI. To measure the improvement of this we need to collect some filesize histograms from real disk images.
- (maybe) #87: store fewer validation hashes in each share, to reduce that 846-byte overhead to 718 bytes.
Our guess is that this will reduce the minimum space consumed to 40960 bytes (41kB), occuring when the filesize is 10134 (10kB) or smaller.
The URI:LIT fix will cover the 0-to-80ish byte files efficiently. It may be the case that we just accept the overhead for 80-to-10134 byte files, or perhaps we could switch to a different algorithm (simple replication instead of FEC?) for those files. We'll have to run some more numbers and look at the complexity burden first.
comment:4 Changed at 2007-07-12T18:59:55Z by warner
- Milestone changed from undecided to 0.5.0
- Owner changed from somebody to warner
comment:5 Changed at 2007-07-14T00:30:37Z by warner
I've fixed the main problems here. My plan is to do some more tests, measure the current overhead (and record the results here), then close this ticket. #87 is a future change, since we want to retain the validation for a while, until we feel super-confident about the intermediate steps.
comment:6 Changed at 2007-07-16T19:25:03Z by warner
copy of a message I sent to tahoe-dev:
I've just upgraded testnet to the most recent code, and have been playing with larger uploads (now that they're finally possible). A couple of performance numbers:
- uploading a copy of the tahoe source tree (created with 'darcs dist'),
- telling the node to copy the files directly from disk, using: time curl -T /dev/null 'http://localhost:8011/vdrive/global/tahoe?t=upload&localdir=/home/warner/tahoe'
- 384 files
- 63 directories
- about 4.6MB of data
- upload takes 117 seconds
- about 30MB consumed on the storage servers
- 0.3 seconds per file, 3.3 files per second
- 39kB per second
With the 3-out-of-10 encoding we're now using by default, we expect a 3.3x expansion from FEC, so we'd expect those 4.6MB to expand to 15.3MB. The 30MB that was actually consumed (a 2x overhead) is the effect of the 4096-byte disk blocksize, since the tahoe tree contains a number of small files.
Uploading a copy of a recent linux kernel (linux-2.6.22.1.tar.bz2, 45.1MB) tests out the large-file performance, this time sending the bytes over the network (albeit from the same host as the node), using an actual http PUT:
time curl -T linux-2.6.22.1.tar.bz2 'http://localhost:8011/vdrive/global/big/linux-2.6.22.1.tar.bz2'
- 1 file
- 1 new directory
- 45.1MB of data
- upload takes 44 seconds
- 151MB consumed on the storage servers
- 1.04MB per second
The 3.3x expansion of a 45.1MB file would lead us to expect 150.3MB consumed, so the 151MB that was actually consumed is spot on.
Downloading the kernel image (on the same host) took place at 4.39MBps on the same host as the node, and at 4.46MBps on a separate host (the introducer).
Please note that these speed numbers are somewhat unrealistic: on our testnet, we have three storage servers running on one machine, and an introducer/vdrive-server running on a second. Both machines live in the same cabinet and are connected to each other by a gigabit-speed network (not that it matters, because the introducer/vdrive-server holds minimal amounts of data). So what we're measuring here is the speed at which a node can do FEC and encryption, and the overhead of Foolscap's SSL link encryption, and maybe the rate at which we can write shares to disk (although these files are small enough that the kernel can probably buffer them entirely in memory and then write them to disk at its leisure).
Having storageservers on separate machines would be both better and worse: worse because the shares would have to be transmitted over an actual wire (instead of through the loopback interface), and better because then the storage servers wouldn't be fighting with each other for access to the shared disk and CPU. When we get more machines to dedicate to this purpose, we'll do some more performance testing.
comment:7 Changed at 2007-07-16T20:22:51Z by warner
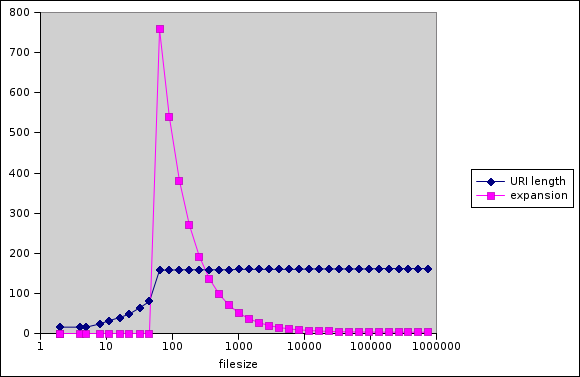
here's a graph of overhead (although I'll be the first to admit it's not the best conceivable way to present this information..): attachment:overhead1.png .
The blue line is URI length. This grows from about 16 characters for a tiny (2-byte) file, to about 160 characters for everything longer than 55 bytes.
The pink line is effective expansion ratio. This is zero for small (<55byte) files, since we use LIT uris. Then it gets really big, because we consume 40960 bytes for a 56byte file, and that consumption stays constant up to a 10095-byte file. Then it jumps to 81920 bytes until we hit 122880 bytes at about 22400-byte files. It asympotically approaches 3.3x (from above) as the filesize gets larger (and the effect of the 4kB blocksize gets smaller).
Changed at 2007-07-16T20:23:34Z by warner
Changed at 2007-07-16T20:38:22Z by warner
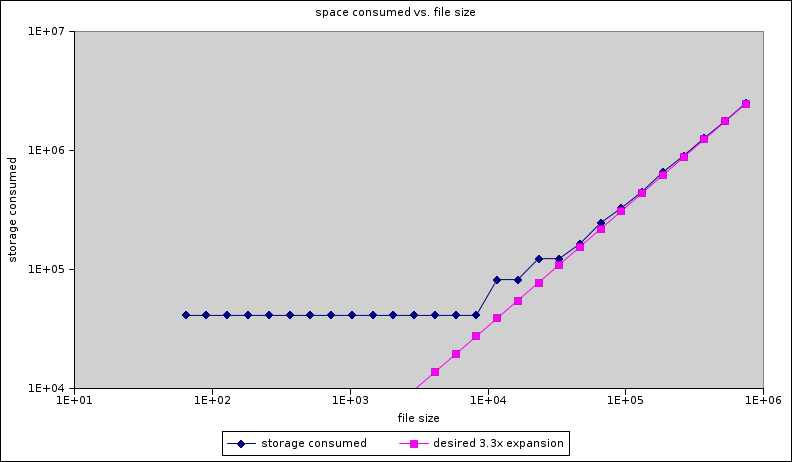
comment:8 Changed at 2007-07-16T20:41:05Z by warner
ok, this one is more readable. The two axes are in bytes, and you can see how we get constant 41kB storage space until we hit 10k files, then 82kB storage space (two disk blocks per share) until we hit 22k files, then the stairstep continues until the shares get big enough for the disk blocks to not matter. We approach the intended 3.3x as the files get bigger, getting too close to care by about 1MB files.
comment:9 Changed at 2007-07-16T20:45:14Z by warner
I'm adding a tool called source:misc/storage-overhead.py to produce these measurements. To run it, use
PYTHONPATH=instdir/lib python misc/storage-overhead.py 1234
and it will print useful storage-usage numbers for each filesize you give it. You can also pass 'chart' instead of a filesize to produce a CSV file suitable for passing into gnumeric or some other spreadsheet (which is how I produced the graphs attached here).
comment:10 Changed at 2007-07-16T20:45:43Z by warner
- Resolution set to fixed
- Status changed from new to closed
and now I'm going to close out this ticket, because I think we've improved the situation well enough for now.
Ooh, it gets worse, I was trying to upload a copy of the 13MB tahoe source tree into testnet (which has about 1620 files, two thirds of which are patches under _darcs/). The upload failed about two thirds of the way through because of a zero-length file (see #81), but just 2/3rds of the upload consumes 1.2GB per storageserver (when clearly that should be closer to 13MB*4/3*2/3, say 11.5MB).
This 100x overhead is going to be a problem...